
In 2024, AI companies like NVIDIA and OpenAI experienced rapid growth. In particular, many investors believed that demand for high-end Graphical Processing Units (GPUs), a special kind of hardware well-suited to developing and running AI models, would continue to grow rapidly. Recent AI models have required bigger GPU clusters in order to begin to “reason” more like the human brain. Companies are training and releasing new innovative LLMs with increasing frequency, such as Meta’s Llama series of models, the first widely popular open source LLMs, and Mistal AI’s Mixtral, the first open source Mixture-of-Experts model. In spite of these innovations, in early 2025, we saw fears of change drive down the values of companies like NVIDIA. Are these “reasoning” models actually the next step towards truly intelligent AI? And why did the release of a low-cost AI model from the Chinese company DeepSeek upset investors?
Thinking about AI
In September 2024, OpenAI announced its new o1 series of models. OpenAI claimed that these models, dubbed “Reasoning Models”, allowed LLMs to think through logical problems like humans do. The actual details of how the o1 model series works have not been disclosed, but OpenAI did explain that it uses a process called “Chain-of-Thought.” Although the models are architecturally similar to previous GPT generations, o1 executes multiple “turns” of inference. What this effectively means is that o1 will generate a response and feed that response back into itself for critique. o1 can even generate multiple different responses, rank their correctness, and choose the best one. It is also trained to break problems down into smaller, more manageable steps and produce separate outputs for each step. The result of all this extra “reasoning” is one final and concise response. While the models still aren’t “thinking” in the traditional sense, they’re able to reason about problems by doing more processing to ensure correctness. If the computer infrastructure could be scaled to match the greater demands of o1, correctness would theoretically improve by 100 times over GPT-4 .

Which brings up the elephant in the room. Running LLMs and generative AI models is already extremely expensive because it requires a massive number of the most powerful GPUs. NVIDIA, the leading manufacturer of GPUs, saw its stock price boom in 2024 due to the increased demand. Increasing the compute time necessary for producing LLM responses also dramatically increases the need for compute. Investors in NVIDIA and other companies supporting heavier AI methods saw this as an opportunity and an advantage, causing valuations to continue to increase. As the first company to publicly release a model like o1, OpenAI held its dominant position, and could charge more without fundamentally changing the underlying model architecture. Companies like Anthropic, xAI, and Google all followed suit, releasing their own reasoning models within a matter of weeks. It seemed like OpenAI and other companies developing and supporting high-compute AI models were going to continue to benefit from LLM growth.
A New Challenger
Then, in January of 2025, the Chinese company DeepSeek launched an LLM that they claimed was created cheaply and quickly—with comparable performance to o1.
DeepSeek previously joined the open-source LLM space with non-reasoning models like DeepSeek Coder. While these LLMs were not revolutionary, they helped hobbyists and smaller companies run LLMs locally and fine-tune them cost-effectively. To improve on o1, DeepSeek’s researchers prioritized data quality over quantity.
Instead of focusing on generating more data, DeepSeek used a small amount of high-quality training data to train smaller LLMs to perform almost as well as much larger models. Then, to train the model, their researchers used techniques for reinforcement learning, a process in which an algorithm ranks the correctness of the LLMs results. This is more efficient than supervised learning, which requires humans to manually rank the output. While OpenAI has not released all of the details of their training methods, it is safe to assume that they used a combination of reinforcement learning and supervised learning during the training of o1. DeepSeek instead trained a base model on their higher quality dataset using these reinforcement techniques with a much shorter fine-tuning pass using supervised learning to improve readability. By using a smaller dataset and more efficient learning techniques during training, DeepSeek was able to train an LLM using much less powerful GPU clusters than prior LLMs. The result was DeepSeek R1: a model almost as competent as OpenAI’s o1 trained for a fraction of the cost. Furthermore, R1 is open-source and much smaller than o1, meaning that almost anyone can run it on high-end consumer hardware without using the most expensive NVIDIA GPUs.
Investors panicked. Stock prices for hardware companies fell. The news media ran headlines with geopolitical overtones claiming that China had bested western companies in AI. Although other companies including Anthropic, the maker of Claude, and Mistral, a French AI startup, had made progress on their own reasoning models, the cost-savings introduced by R1 were not initially matched.
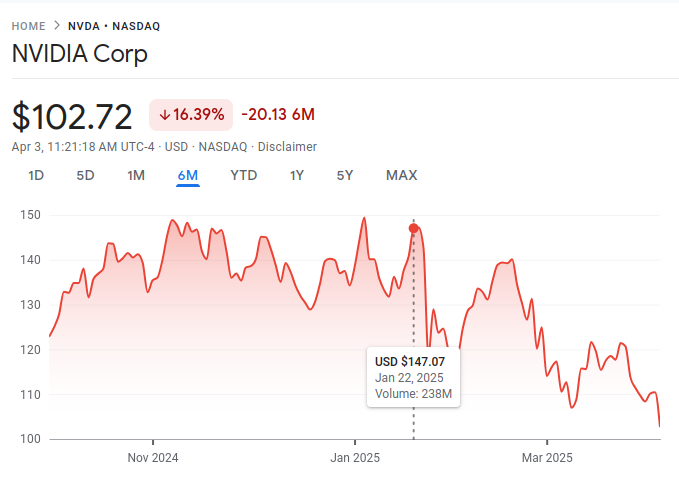
Cheaper Hardware, More Brain Power
Soon, competitors to R1 began to appear. Qwen QwQ, a reasoning model developed by China’s Alibaba, is an order of magnitude smaller than R1 but performs comparably on most LLM benchmarks. It’s also an incredibly competent reasoning model and can be run on consumer-grade hardware. Since both R1 and QWQ are open-source models, it’s very likely that we’ll continue to see innovations built on their work.
The real question going forward in the wake of these models is whether the lofty claims by hardware companies like NVIDIA about the urgent need for more GPUs will hold up. These new models still rely on GPUs to be trained, but they’ve shown that high performance LLMs can be trained and deployed with less computing power than previously thought. Big AI players like OpenAI are struggling to keep their huge models running as use and capabilities expand. Sam Altman, CEO of OpenAI, has claimed that even with OpenAI’s massive success and multiple paid tiers, ChatGPT is not profitable and effectively loses money on each prompt return.
Although the release of these capable models that can perform on low cost hardware unsettled financial markets, they could boost the US and global economy in other ways. Models that can be trained and deployed for less can be used in many more products, making the incorporation of LLMs into technology stacks easier than ever. And with more engineers able to use these models, we can expect more innovation to be built on them. And we have yet to see how western AI companies will respond. For example, what happens when lightweight models are supported by the gigantic GPU clusters being built by OpenAI and xAI? While the emergence of these low cost reasoning models has made the ultimate winners in the AI race less clear, the wider applicability has increased the potential for overall economic growth.