
Neural networks are machine learning algorithms inspired by biological neural circuits. The human brain is incredibly complex. Lucky for software engineers, neural networks in ML are less complex (at least slightly)!
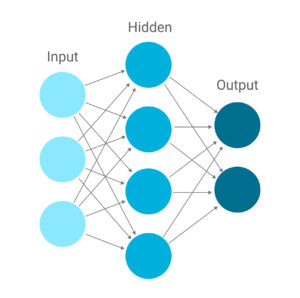
You may have seen a diagram like the one above when learning about neural networks. But what do those circles and arrows really mean? Let’s take a walk through history to explain.
Neural networks, in theory
The theoretical neural network was first proposed by the psychologist-logician duo of Warren McCulloch and Walter Pitts back in 1943 in their landmark article, “A Logical Calculus of the Ideas Immanent to Nervous Activity.” They were interested in modelling the nervous system as a combination of mathematical functions.
In the diagram above, the circles represent “neurons,” a single processing unit of a neural network. The neurons store a set of random numbers, called “weights” inside of them. Each neuron receives some input numbers, represented by the pointed ends of each arrow, or “synapse.” The input numbers get multiplied by the weights and added together, and the result of that calculation is the output of the neuron. By hooking many of these neurons together in what we call “layers,” we create a “neural network.”
So what goes into the network, and what comes out?
An input is some sort of data, be it an image, a series of numbers, or a string of text. The output will be whatever the ML engineer wants to know about the data, or what the ML engineer wants the neural network to be able to say about the data. For example, an input could be portraits of pets, and the outputs could be “cat” or “dog,” with the neurons representing the probability that the photo is of a “cat” or “dog.”
Early work on artificial neural networks
This example actually describes one of the first neural networks ever created. A psychologist named Frank Rosenblatt created the “perceptron” in the 1950s, which aimed to classify photos into different categories.

How did it work? The neurons in the network became adjustable potentiometers, and the synapses became wires. At the end of the network, the brightest output bulb represented the category that the image had been classified into.
Rosenblatt “trained” his perceptron by showing it many inputs and checking the correctness of its output. When the network was wrong, he went back and manually adjusted the weights of the potentiometers along the way to get the network to produce the correct output. After doing this process over and over again, adjusting the weights according to an optimization algorithm called stochastic gradient descent, the perceptron was trained to correctly recognize patterns.
Other researchers made multilayer perceptrons that contained multiple internal layers of computation trained with SGD. However, research stagnated for decades after this early work on perceptrons.
In the 1980s, several different researchers, including Paul Werbos and David Rumelhart, incorporated a mathematical technique called backpropagation into multilayer perceptron training, which allowed information about whether the network outputted correctly or incorrectly to be incorporated into the interior (hidden) layers during training. The machine could “learn” on its own.
Convolution and Deep learning
In the late 1980s and 1990s, a type of neural network designed for image processing called convolutional neural networks (CNN) was developed. Yann LeCun trained CNNs using backpropagation to create the series of networks known as LeNet, which excelled at recognizing handwritten numbers. By the end of the decade, CNNs were reading over 10% of all checks in the US.
However, there were not many other realistic applications of neural networks. The trouble was that constructing a network required careful engineering to take real-life input–photos, financial information, anything–and figure out some way to represent it as numbers to be fed into the neural network.
Then, advancements in processing for computer vision, such as the spread of Graphical Processing Units (GPUs) from NVIDIA and the availability of large image datasets, led researchers to invest in deep learning, meaning neural networks with many hidden layers, which allowed the machine to have specific functions for recognizing small details in data. The machine could incorporate more layers to automatically learn how to represent real-world data as inputs for deeper layers in the network.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton won the ImageNet 2012 competition for their deep convolutional neural network, which kicked off the modern AI boom. Hinton went on to win the 2024 Nobel Prize in Physics along with Yoshua Bengio and Yann LeCun for their work on deep learning.
Attention
In 2017, a team of researchers at Google published a paper called “Attention Is All You Need” (Vaswani, et al). They proposed a network called the Transformer, which greatly reduced the amount of computation needed to represent input and output for previously difficult-to-manage data, like raw text. Transformers encode texts as small lists of numbers called tokens. On top of this, Transformers factor in the specific placement of tokens within a body of text, which helps the network figure out which tokens are most important for creating a good output.
The Transformer now underpins most contemporary large language model (LLM) technology, like that developed by OpenAI and Anthropic, as it allows the network to “pay attention” to relevant information that might have been mentioned much earlier. Transformers can now even be applied to non-textual inputs, like images and audio.
Today
Neural networks have proliferated into many areas of technology and life today, performing simple and complex, broad and specific tasks. In computer vision, models like You Only Look Once (YOLO) allow the quick detection and classification of objects within images. In audio processing, models like Spleeter can separate musical pieces into “stems”, allowing musicians to create instant acapella or instrumentals from existing songs. NASA is using neural networks to identify newly discovered galaxies in data that is decades old.
From the bulky perceptron, which took up an entire room, we are now able to run neural networks in the cloud or on edge devices like the NVIDIA Jetson. Neural networks have evolved from an academic curiosity into an indispensable tool that continues to reshape how we solve complex problems and interact with technology.