
What is Machine Learning?
Over the past few years, data scientists have been making remarkable breakthroughs in the field of machine learning, a process that allows humans to quite literally teach computers how to recognize things. As children, humans learn to recognize and categorize things like trees, planes, and dogs by being exposed to dozens or even hundreds of examples of each in the wild. Over time and with guidance from the adults around us, w e learn to recognize what makes a dog different from a cat or a tree different from a bush and we start to associate names and functions with these things — that cylindrical ceramic container on your desk is a mug that stores coffee; the annoying creature that wakes you up every morning is a bird, and so on. Computers don’t have the benefit of a childhood to learn these things, but machine learning mimics this process: a computer model is “trained” on numerous examples of whatever it is you’d like your computer to learn to recognize until it is able to figure out the rules that make things, well … things. Those things might range from new galaxies in old astrological data to rare and dangerous diseases in patients. The possibilities for machine learning to change the world are as limitless as human imagination.
e learn to recognize what makes a dog different from a cat or a tree different from a bush and we start to associate names and functions with these things — that cylindrical ceramic container on your desk is a mug that stores coffee; the annoying creature that wakes you up every morning is a bird, and so on. Computers don’t have the benefit of a childhood to learn these things, but machine learning mimics this process: a computer model is “trained” on numerous examples of whatever it is you’d like your computer to learn to recognize until it is able to figure out the rules that make things, well … things. Those things might range from new galaxies in old astrological data to rare and dangerous diseases in patients. The possibilities for machine learning to change the world are as limitless as human imagination.
At Daedalus we are exploring new and innovative ways to incorporate machine learning into our designs. Currently, one of the most valuable applications of machine learning relates to computer vision, where models can be used to identify, categorize, and locate specific things in images and videos. For example, a home security system could be trained to alert its owners to when an unrecognized person is at the door. Or a computer for a fabrication line could be trained to detect faulty assemblies with nothing more than a webcam. Or a disaster recovery drone could be trained to identify survivors of natural disasters from aerial footage more effectively than a human could. This type of model — ones that can be trained to find specific objects within an image — are called “Object Detection” models, and they are increasingly being used in all aspects of our lives.
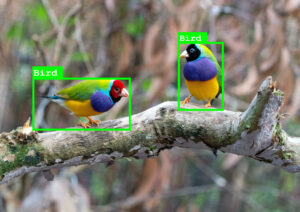
Machine Learning Challenges
One of the most difficult challenges to overcome in creating any kind of machine learning model is in finding thousands (or more) of examples of the thing that you want your model to learn to recognize. This training data is increasingly becoming a vital resource in the tech industry and entire companies have formed just to collect and distribute these data. Just as it takes exposure to hundreds or thousands of examples for a human to learn what birds are or how particle physics works, machine learning models need to be trained on hundreds of thousands of data points. Though many organizations have worked to create publicly accessible datasets, at Daedalus we’ve learned that these datasets aren’t particularly useful for more specialized tasks. And while it is certainly possible to aggregate specialized datasets by hand, it would involve capturing thousands of images and manually labeling them with the information the model needs in order to learn. This isn’t really feasible and certainly would not be very easy.
So at Daedalus, we’ve tackled this problem by using a new type of data called synthetic data. Instead of painstakingly photographing whatever we want our models to detect, we use 3D simulations to render photos that look close enough to our desired objects to allow for machine learning.
While it may sound a bit surreal to think that a computer can learn what something is without ever actually seeing it, humans do something similar every day. We are easily able to recognize cartoon drawings or graphical icons and associate them with physical objects. For example, the pedestrian image that appears as an LED icon on traffic signals is made of basic shapes, but we are still able to recognize it as a person because of the baseline features. Synthetic data utilizes the idea of distinguishing baseline features to help a model extrapolate what it learns from simulations into real world applications.
To accomplish this we use a tool called Blender that allows us to create highly detailed 3D models of whatever it is that we want our model to learn to recognize. Blender also has an entire scripting environment built in, which means that every single aspect of Blender can be automated, including the creation of full 3D scenes and the extraction of object locations within rendered images. This allows us to effortlessly generate a full list of context specific examples to feed directly into our model without any kind of human involvement. An entire dataset of localized objects can be created with just a click of a button.
But relying on simulations to represent our objects’ baseline features introduces another challenge. We have to ensure that our synthetic data is accurate enough to highlight the important features of the objects we want to detect, but still varied enough that our model doesn’t inadvertently learn to only recognize Blender’s simulated data. We achieve this through something called Domain Randomization, a process wherein we deliberately introduce variability into our synthetic images to help the model understand the various conditions in which our objects can be found.
We render our desired objects in front of different image backgrounds to place them in new environments. We can also create a full range of possible lighting conditions for our desired objects by varying light intensities, colors, and shapes. We can even add “noise” objects that we don’t wish our model to detect so that it can learn to avoid false positives. All of this variability helps the model to understand what is and isn’t important for identifying objects. For example, a box is still a box regardless of how it is rotated, lit, or placed within a scene. Domain randomization allows us to create varied examples to show our model, including ones that would never be found in the real world. By randomizing our synthetic data we can effectively have our model treat real world conditions as yet another random variation in our domain.

Ideally, our model will learn to recognize the desired object (the package) and to distinguish it from the background and other noise, as pictured below.
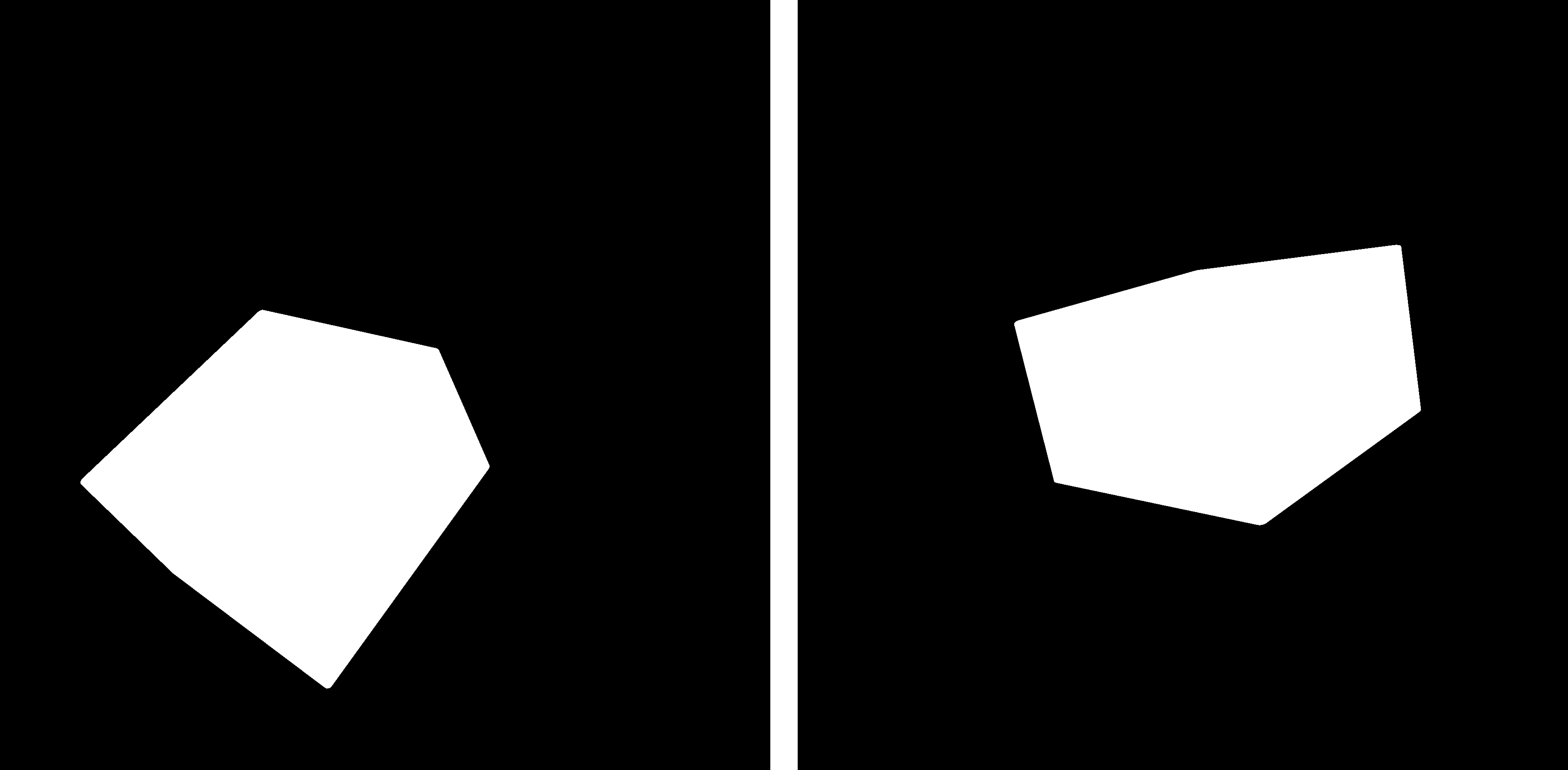
This technique is immensely powerful for applications in which little pre-existing training data exists. If we wanted to build an AI home security system that could send a notification to a user’s phone when a package has been delivered, we’d need thousands of photos of packages on doorsteps, with data entered by hand related to the pixel coordinates of each package, and in a format the model could understand. Collecting data like that manually would take days, if not months. To make matters more complicated, the ethics of how AI training data is collected is becoming more of a concern. Many homeowners would be very unhappy to discover if their home security system were recording pictures of packages on their doorsteps and sending them off to train a model without their consent. Synthetic data solves both of these problems, as the rendering software generates completely new and unique data along with all the necessary pixel locations for the model to learn from.
Exciting Endeavors Ahead
Synthetic data is already being used in a wide variety of technologies. Google’s Waymo has been using simulations to train self-driving cars without the need to rely on potentially unsafe prototypes being driven in the real world. Banks such as J.P. Morgan use synthetic data to help detect fraudulent activity without violating the privacy of customers or consumer protection laws by harvesting actual financial data. In some instances models trained on synthetic data have been shown to perform better than models trained solely on real-world data. By all indications synthetic data is going to become increasingly relevant as AI becomes a bigger part of our lives. At Daedalus we’re very excited by the results we’ve been getting from our synthetically trained models, and we can’t wait to discover what we can accomplish next with this revolutionary new technique.